مقدمة
في هذا المقال سنتعرف سويا على موضوع مهم في علم معالجة اللغات الطبيعية (NLP) وهو Word embeddings وكيفية تطبيقة باستخدام طريقة ال CBOW والتي سنبرمجها معا من الصفر باستخدام لغة البرمجة بايثون (Python)
بعض المتطلبات المسبقة
قبل ان نبدا معاً يجب ان نعرض بعض المتطلبات المسبقة لفهم المقال بشكل سهل وسلسل
- Python
- Deep Learning
- Gradient descent
ترجمة بعض المصطلحات العلمية
خلال هذا المقال سوف نستخدم المصطلحات العلمية بلغتها الاصلية حيث ان ترجمتها سيضع بعض الغموض و سيصعب عليك البحث والتعلم في هذا الموضوع فيما بعد لذلك سأكتبها كما هي وسأضع هنا بعض الترجمات التي يمكن العثور عليها
- Vector : مُتجه
- Word2Vec : تمثيل الكلمات لمُتجهات
- Continuous Bag of words (CBOW) : واحدة من الطرق المستخدمة لتمثيل الكلمات كمتجهات
- Natural language processing (NLP) : معالجة اللغات الطبيعية
- Gradient descent : هي الخوارزمية المستخدمة لتحسين الخطأ الناتج من التعلم قدر الإمكان
- Deep Learning : التعلم العميق، وهو فرع من فروع علم الذكاء الاصطناعي
- Integers: عدد صحيح
مشكلة تمثيل الكلمات
في ال Deep learning يجب أن تكون البيانات المستخدمة في التعلم على هيئة أرقام ،فعلى سبيل اذا اردت بناء model للتعرف على مدى رضا العملاء عن خدمة معينة من خلال تعليقاتهم، فستحتاج بلا شك لبيانات مكونة من كلمات (نصوص التعليقات المكتوب بواسطة العملاء) ، ولكي تبدأ عملية التعلم فعليك تحويل تلك النصوص لأرقام حتى يستطيع ال model التعامل معها، وهنا سيظهر سؤال كيف يمكن تمثيل النصوص لأرقام؟
الطرق المختلفة لتمثيل النصوص الى ارقام
هناك العديد من الطرق لتحويل النصوص سنعرض هنا بض منها ، وسنطبق في النهاية بطريقة ال CBOW
Integers
في هذه الطريقة نستخرج الكلمات من النصوص المتوافرة لدينا بدون تكرار،وبعد ذلك نضع لها رقم صحيح مميز لها . على سبيل المثال لنتخيل أن النصوص التالية هي البيانات والمطلوب تمثيلها بطريقة الأعداد الصحيحة
2- البرمجة تفتح أفق جديدة للعالم
3- أنا أحب تطوير تطبيقات جديدة
الكلمات الموجودة في المثال بدون تكرار :
| الكلمة | الرقم |
|---|---|
| أنا | 1 |
| أحب | 2 |
| تعلم | 3 |
| البرمجة | 4 |
| تفتح | 5 |
| أفق | 6 |
| جديدة | 7 |
| للعالم | 8 |
| تطوير | 9 |
| تطبيقات | 10 |
قد تكون هذه الطريقة حلت مشكلة تمثيل البيانات ولكن تظل هناك مشكلة حقيقية في أن الأرقام التي تمثل الكلمات لا تحمل أي معني، فيمكن تبديل الارقم المقابلة للكمات باي رقم اخر ،كمثال يمكن التبديل بين كلمتين (أنا:1 ، تعلم:3) في الجدول بالأعلى لتصبح (انا :3 ، تعلم:1)
One-hot Vectors
فهذه الطريقة تاخد كل كلمة رقم خاص بها ، ولكن هنا يتم تمثيل الكلمة من خلال متجه (Vector) جميع عناصره قمها صفر ما عدا العنصر في المكان القابل لرقم الكلمة فيكون قيمته بصفر ، شكل هذا المتجه $$M*1$$ حيث M عدد الكلمات في النص بدون تكرار. ليكون الامر اوضح دعونا نطبق على المثال بالاعلى تلك الطريقة
| أفق | |
|---|---|
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| 5 | 0 |
| 6 | 1 |
| 7 | 0 |
| 8 | 0 |
| 9 | 0 |
| 10 | 0 |
مميزات تلك الطريقة
- بسيطة لا تحمل تعقيد لبرمجتها
عيوب تلك الطريقة
- حجم المتجهات يمكن أن يكون ضخم فتخيل مثلا عدد الكلمات 12M
- المتجهات في هذة الحاله لاتحمل ايضا معني خاص للكلمة يعبر عنها
Word Embeddings
لتبسيط هذا المفهوم ، تخيل ان هناك خط يزيد فيه المعنى الايجابي كلما اتجهنا يمينا، ويزيد فيه المعنى السلبي كلما اتجهنا لليسار كما هو موضح بالاسفل . فبهذه الطريقة يمكننا تمثيل الكلمة من خلال متجه ذات بعد واحد 1*1 يعبر عن مدى إيجابية او سلبية الكلمة فعلى سبيل المثال إذا اخترنا رقم عشوائي (مثلاً 3) فبالتأكيد سيكون هذا الرقم تمثيل لكلمة إيجابية وعلى العكس إذا اخترنا رقم أقل من الصفر.

بنفس الطريقة تخيل أن هناك بدل الخط، محورين محور رأسي محور أفقي كما هو موضح بالاسفل،بحيث تكون الكلمة تعبر عن شئ مادي كلما اتجهنا لاعلى، و تعبر الكلمة عن شئ اكثر معنوية كلما اتجهنا لأسفل. يمكننا التعبير عن الكلمة في هذه الحالة بمتجه بشكل 2*1 ، كمثال يمكن تمثيل كلمة كلب بالمتجه [1.09, 0.57] . في هذه الحالة أصبح المتجه يعبر بشكل أكبر عن الكلمة ، فكلما زادت قيمة المحور الأفقي كلما زادت المني الإيجابي للكلمة ،وكلما زادت قيمة المحور الرأسي أصبحت الكلمة أكثر مادية، وهكذا في باقي الاتجاهات. وبذلك أصبح التمثيل يعبر بقوة اكثر عن الكلمة. وكلما زادت المحاور او كما نسميها الابعاد التي تمثل الكلمة كلما اصبح هذا التمثيل يعبر بقوة اكثر عن الكلمة.

مميزات تلك الطريقة
- أصبحت المتجهات في هذة الطريقة حجمها اقل فعادة تكون بين 100~1000 ولكن في الطريقة السابقة ربما تتجاوز المليون
- أصبح المتجه يحمل معنى لكل كلمة
- أي المسافة بين الكلمات القريبة في المعنى اقصر
- مثال : متجه كلمة “شجرة” تقريبا يساوى المتجه الممثل لكلمة “أشجار” ويختلف تماماً عن المتجه الممثل لكلمة “تذكرة”
- تستطيع استخراج التشابه الجزئي بين الكلمات
- مثال: كلمة “باريس” بالنسبة لكلمة “فرنسا” مثل كلمة “القاهرة بالنسبة لكلمة ؟ فاذا كنا نمتلك Word Embeddings صحيحة فسيكون الناتج كلمة “مصر”
والان بعد ان تعرفنا على الفكرة الاساسية التي تعتمد عليها ال word embeddings كيف يمكننا حسابها ؟ فبالطبع لن نرسم محاور ونضع كل كلمة على تلك المحاور ، وهنا ياتي دول الDeep learning ، سنتعرف في الفقرات القادمة على الشهر الطرق المستخدمة لحساب تلك المتجهات
الطرق المختلفة للحصول على ال Word Embeddings
والان بعد ان تعرفنا على الفكرة الاساسية التي تعتمد عليها ال word embeddings كيف يمكننا حسابها ؟ فبالطبع لن نرسم محاور ونضع كل كلمة على تلك المحاور ، وهنا ياتي دول الDeep learning ، سنتعرف في الفقرات القادمة على الشهر الطرق المستخدمة لحساب تلك المتجهات
١- طرق بسيطة
المشترك في هذه الطرق الثلاثة إن كل كلمة لها متجه واحد فقط بغض النظر عن موقع الكلمة في الجملة (مثال: رأيت عين ما)
٢- يوجد للذبابة أكثر من عين
معنى كلمة "عين" في الجملة الاولى تختلف عن معنى "عين" في الجملة الثانية ولكن لهما نفس قيمة المتجه
- Word2Vec (Google, 2013)
- Continuous bag-of-word (CBOW)
- Continuous Skip-gram/Skip-gram with negative sampling (SGNS)
-
Global Vectors (GLoVe) (Stanford, 2014)
- fastText (Facebook, 2016)
- المميز في هذة الطريقة انها تستطيع حساب متجهات لكلمات لم تراها من قبل لأنها تعمل على الحروف بدلاً عن الكلمات
٢- طرق أكثر تعقيداً
المشترك في هذه الطرق الثلاثة أن حساب المتجه للكلمة متغير بحسب معناها في الجملة، فإذا طبقنا على الثال السابق ، سيصبح لكلمة "عين" في الجملتين متجهين مختلفين
- BERT (Goole, 2018)
- ELMo (Allen Institute for AI, 2018)
- GPT-2 (OpenAI, 2018)
ما هي طريقة ال CBOW
CBOW هو طريقة نستطيع بها حساب الـ Word emmbeddings ، وتعتمد هذه الطريقة على تدريب model للتنبؤ بالكلمة من مجموعة الكلمات المحيطة بتلك الكلمة. مثال :
الكلمات المتاحة لل model للتنبؤ :
فيجب أن يختار ال model هنا كلمة كلب
كيفية تحضير الأمثلة وال dataset
قبل البدء في شرح هذا بالتفصيل ، هناك بعض المفاهيم التي يجب معرفتها
تسمى الكلمة المراد التنبؤ بها ب (center word)، وتسمى الكلمات المحيطة بالكلمة من اليمين و اليسار بال (Context Word) ، عدد الكلمات المستخدم على أي جانب من بال (context half-size)، ويرمز لها بالرمز (C) ، ويطلق على مجموع (Context word + center word) بال (windows) ويتم حسابه باستخدام هذة المعادلة $$2*c + 1$$ مثال :
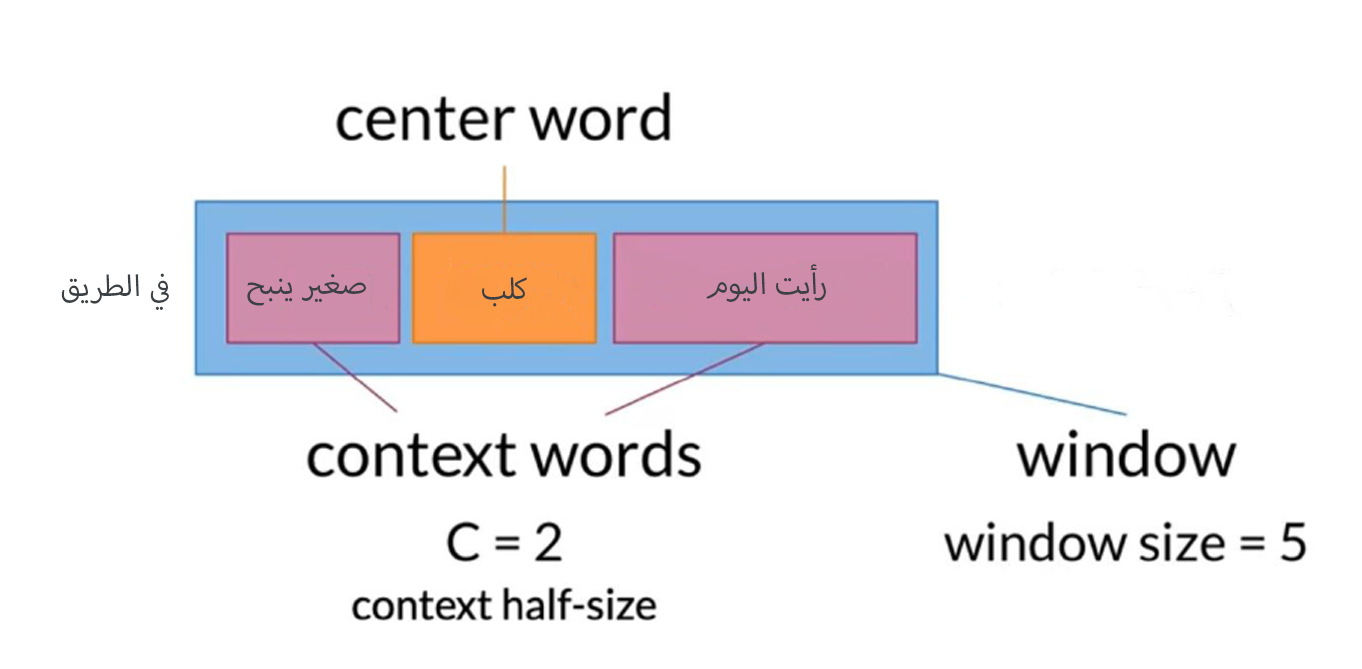
شكل ال Dataset
لنستطيع تطبيق طريقة ال CBOW يجب أن تكون النصوص بشكل معين، وهو أن تكون ال (Context words) هي المدخلات لل Model وتكون ال المخرجات او ال labels هي ال (Ccenter word) ، فلنفترض أن النصوص بالاسفل سنستخدمها في عملية التدريب، و سنستخدم (context half-size) يساوي 1
فستكون ال Dataset بهذا الشكل بالاسفل ، حيث سيرمز للمدخلات بالرمز X والمخرجات بالرمز Y
| X | Y |
|---|---|
| القراءة معرفية | عملية |
| عملية تستند | معرفية |
| معرفية على | تستند |
| تستند تفكيك | على |
| على رموز | تفكيك |
| تفكيك تسمى | رموز |
| رموز حروفا | تسمى |
| تسمى لتكوين | حروفا |
| حروفا معنى | لتكوين |
| لتكوين والوصول | معنى |
| معنى إالى | والوصول |
| والوصول مرحلة | إالى |
| إلى الفهم | مرحلة |
| مرحلة والإدراك | الفهم |
| الفهم . | والإدراك |
والآن بعد ان عرفنا ما هو الشكل المفترض لـ Dataset ، هناك اسئلة حلو كيفية تحويل تلك النصوص لأرقام ؟ وماهو الهيكل لشبكة التعلم العميق ؟ وكيفية استخراج ال Word Embeddings ? وكيفية تقييم جودتها ؟ ، كل هذا سنجيب عليه عمليا في الفقرات التالية
معالجة النصوص (Data preprocessing)
دائما ما تحتوي البيانات على اشياء لا نرغب بها ، او اشياء يجب تعديلها لتناسب ال modell الخاص بنا. في حالة النصوص قد تحتوي على علامات ترقيم مثلا (:,.!? ..etc), أو قد تحتوي على رموز تعبيرية مثل (😀😂😌❤️), أو هاشتاج مثلا (#NLP, #Python), أو قد تحتوي على روابط مثل (gooogle.com - github.com)
وبالنسبة للغة العربية بالإضافة للمشاكل السابقة قد تحتوي على علامات تشكيل مثلا (الكسرة والسكون و الشدة و...), وقد يكتب البعض الياء المنقوطة بدلا من الياء الغير منقوطة والعكس او الكاف الفارسية بدلا من الكاف وهذا سيخلق العديد من المشاكل من ضمنها تكرار الكلام مثلا (التي - التى) ستصبح كلمتين مختلفتين بسبب اختلاف الياء بالخطأ. و الحل ؟!
يعتمد الحل على التطبيق الذي تعمل عليه، ماالذي يجب عليك الاحتفاظ به و مالذي يجب عليك تغييره. مثلا لو افترضنا اننا نعمل ل انشاء word embeddings خاصة بالغة العربية الفصحى او اى تطبيق سيكون فيها علامات التشكيل فيجب أن نترك تلك العلامات. اما اذا افترض أننا نعمل على تطبيق يستخدم لغة عامية فنستطيع أن نزيل علامات التشكيل، فالعامية لا تحتاج علامات تشكيل بصورة كبيرة. ايضا يجب عليك ان تعرف هل سيكون مثلا الرموز التعبيرية مؤثرة في التطبيق أم لا. كل هذه الامور يجب ان تكون في ذهنك قبل بدء عملية معالجة النص
في هذا المقال سنستخدم فقط الحروف العربية والنقطة، وسنبسط اكثر اللغة أي سنزيل علامات الترقيم، و سنستبدل بعض الحروف التي ستعمل على تكرار كلمات بنفس المعنى مثلا (أ-إ-آ)
١- إزالة علامات الترقيم
سنستخدم هنا مكتبة re وهي اختصار ل (Regular expression) وهو مفهم مهم جدا يجب تعلمه ، لأنه يسهل العديد من العمليات على النصوص
import re
arabic_diacritics = re.compile("""
ّ | # Tashdid
َ | # Fatha
ً | # Tanwin Fath
ُ | # Damma
ٌ | # Tanwin Damm
ِ | # Kasra
ٍ | # Tanwin Kasr
ْ | # Sukun
ـ # Tatwil/Kashida
""", re.VERBOSE)
def remove_diacritics(text):
text = re.sub(arabic_diacritics, '', text)
return text
مثال
text = 'هَلْ غَادَرَ الشُّعَرَاءُ منْ مُتَـرَدَّمِ'
print(remove_diacritics(text))
النتيجة
'هل غادر الشعراء من متردم'
٢- تبسيط حروف اللغة
هنا سنستبدل الحروف التي يمكن كتابتها بأكثر من شكل واستبدالها بشكل واحد فقط للتبسيط مثل te (إ-أ-آ) سنستبدله ب [ا]
def normalize_arabic(text):
text = re.sub("[إأآا]", "ا", text)
text = re.sub("ى", "ي", text)
text = re.sub("ة", "ه", text)
text = re.sub("گ", "ك", text)
text = re.sub("وال", "و ال", text)
return text
مثال
text = 'أحب لعب كرة القدم وگرة السلة'
print(normalize_arabic(text))
النتيجة
'احب لعب كرة القدم وكرة السلة'
٣- النصوص المختلطة
تكون النصوص العربية أحيانا بها حروف وعلامات ترقيم واحيانا بها ابجديات من لغات اخرى. لذلك هن سنستخدم المكتبة re لنستخرج فقط الحروف العربية والنقطة
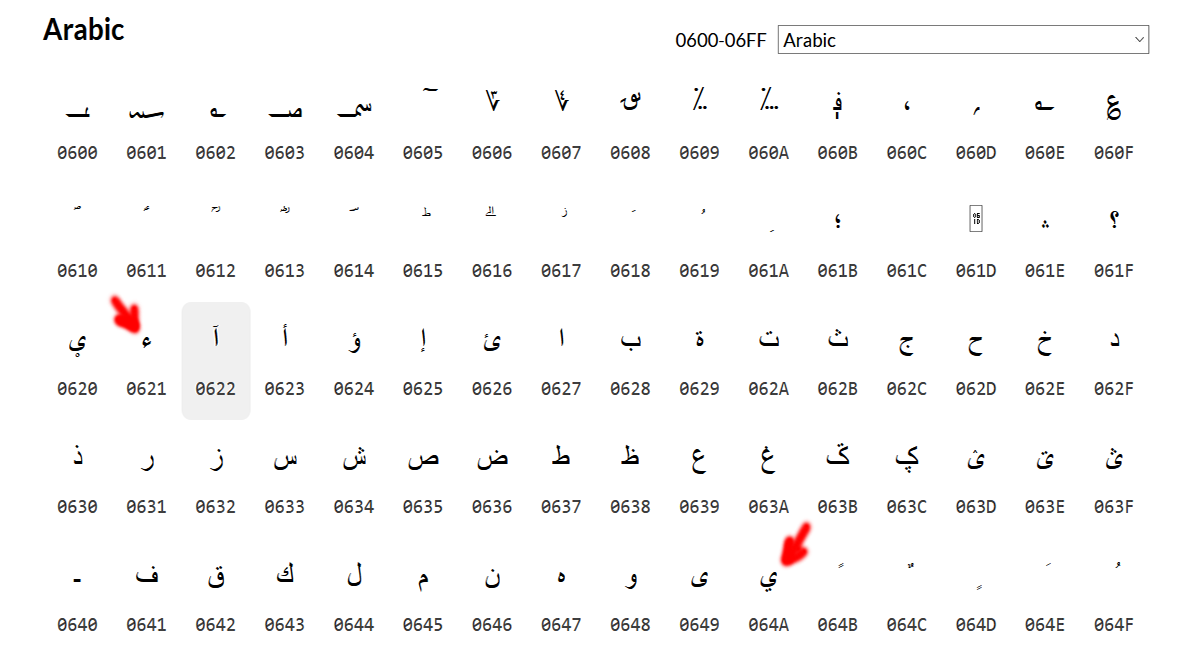
اذا استخدمنا الجدول بالصورة لنعرف الكود المقابل للحروف العربية، سنرى انها تقع بين الحرفين (ء-ي) أي بين الكود (0621-064A)
def get_arabic_and_full_stop(text):
text = re.findall(r'[\u0621-\u064a]+|\.', text)
return text
مثال
text = 'أحب قيادة السيارات من نوع BMW M850 .'
print(get_arabic_and_full_stop(text))
النتيجة
['أحب', 'قيادة', 'السيارات', 'من', 'نوع', '.']
سنضع كل النصوص التي عالجناها في هيئة list بحيث يسهل التعامل معها، واستخراج ال (center words) و (context words), وتحويلها إلى الشكل المطلوب
٤- نوع النصوص المستخدمة في التدريب (Dataset)
هناك العديد من النصوص التي يمكن تحميلها من المواقع المختلفة، اخترت هذه النصوص لسهولة التعامل معها واستخدامها. معظم هذه النصوص من جرائد ومقالات. خلال العمل في هذا المشروع سنضع أي نصوص في المجلد (data)
تلك هي خريطة المجلدات في المجلد (data) بداخل كل مجلد يوجد العديد من الملفات المكتوبة باللغة العربية، والتي سنعالجها وكما رأينا بالاعلى ، لتصبح جاهزة للخطوة القادمة
├───data
│ ├───articlesSports
│ ├───Echoroukonline
│ └───Khaleej-2004
│ ├───Economy
│ ├───International news
│ ├───Local News
│ └───Sports
بعد ان عرفنا كيف سنعالج النصوص ، لنضع الآن كل ما تعلمناه سابقا، لنفتح الملفات ونعالج النصوص
data = []
root = '.\\data'
# get all files
files_paths = [ os.path.join(path, name) for path, subdirs, files in os.walk(root) for name in files]
# loop over files and process them, then append them to the data list
for file_path in files_paths:
f = open(file_path, 'r', encoding='utf-8')
for line in f :
text = remove_diacritics(line)
text = normalize_arabic(text)
text = get_arabic_and_full_stop(text)
data += text
f.close()
والآن بعد حولنا جميع النصوص ووضعناها في list يجب علينا الآن أن نحولها ما شرحنا في هذه الخطوة شكل ال Dataset ولكن تحويلها وتخزينها في الذاكرة هكذا لن يكون عملي حيث أن عدد الكلمات اكثر من 40M لذلك سنستخدم طريقة (Sliding window) او بالعربية إزاحة النافذة ونستخدم ايضا ال generators وهو ميزة رائعة من بايثون ستساعدنا للتعامل مع تلك البيانات الكبيرة، إذا لم تسمع عنها من قبل يجب أن تتعلمها فهي جزء مهم.
def get_windows(words, c):
i = c
while i < len(words) - c:
center_word = words[i]
context_words = words[(i-c):i] + words[(i+1):(i+c+1)]
yield center_word, context_words
i += 1
مثال
gen = get_windows(['احب' ,'قيادة' ,'السيارات' ,'و' ,'احب' ,'قيادة' ,'الدراجات'],1)
for center, context in gen :
print(f'{center}\t{context}')
النتيجة
قيادة ['احب', 'السيارات']
السيارات ['قيادة', 'و']
و ['السيارات', 'احب']
احب ['و', 'قيادة']
قيادة ['احب', 'الدراجات']
تحويل النصوص الى one-hot vector
ولنبدأ بتدريب ال model يجب تحويل الصورة في المثال السابق إلى أرقام. سنستعمل في هذا طريقة one-hot vectors
اولا استخراج الكلمات بدون تكرار . مثال
"أحب قيادة السيارات و أحب قيادة الدراجات"
الكلمات بدون تكرار
أحب - قيادة - السيارات - و - الدراجات
بد تحويلها ستون بهذا الشكل
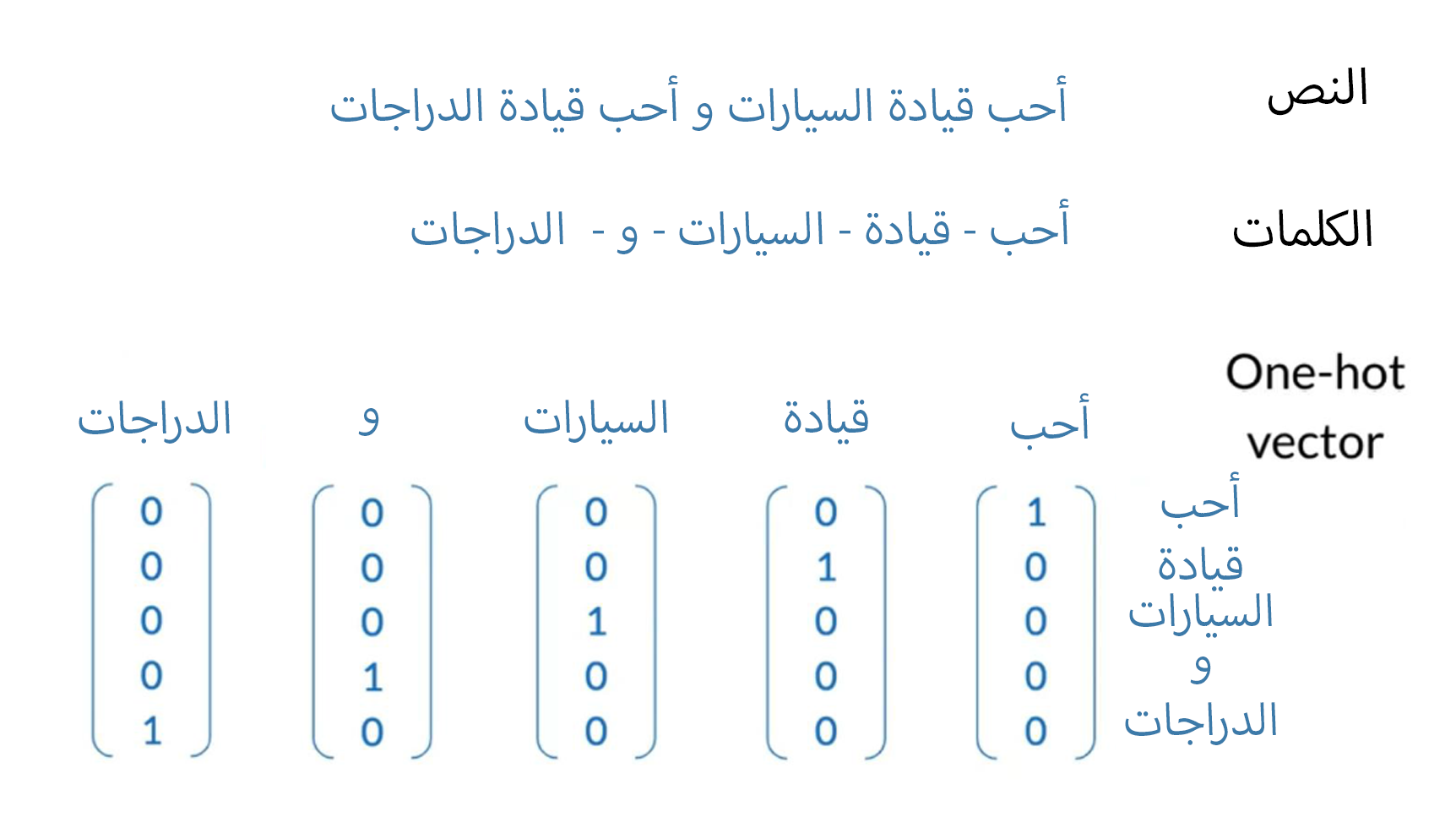
جيد بد حولنا الكلمات في النصوص الي one-hot vectors كيف شكل المدخلات (Cotext words) التي حولناها الى ال model للتعلم، لنفترض أن لدينا هذا المدخل
['احب', 'السيارات']
لتحويله الي vector واحد فقط بدلا من أربعة، سنجتمع قيم ال vectors ثم نقسمها على عددها، لتصبح بذلك الشكل
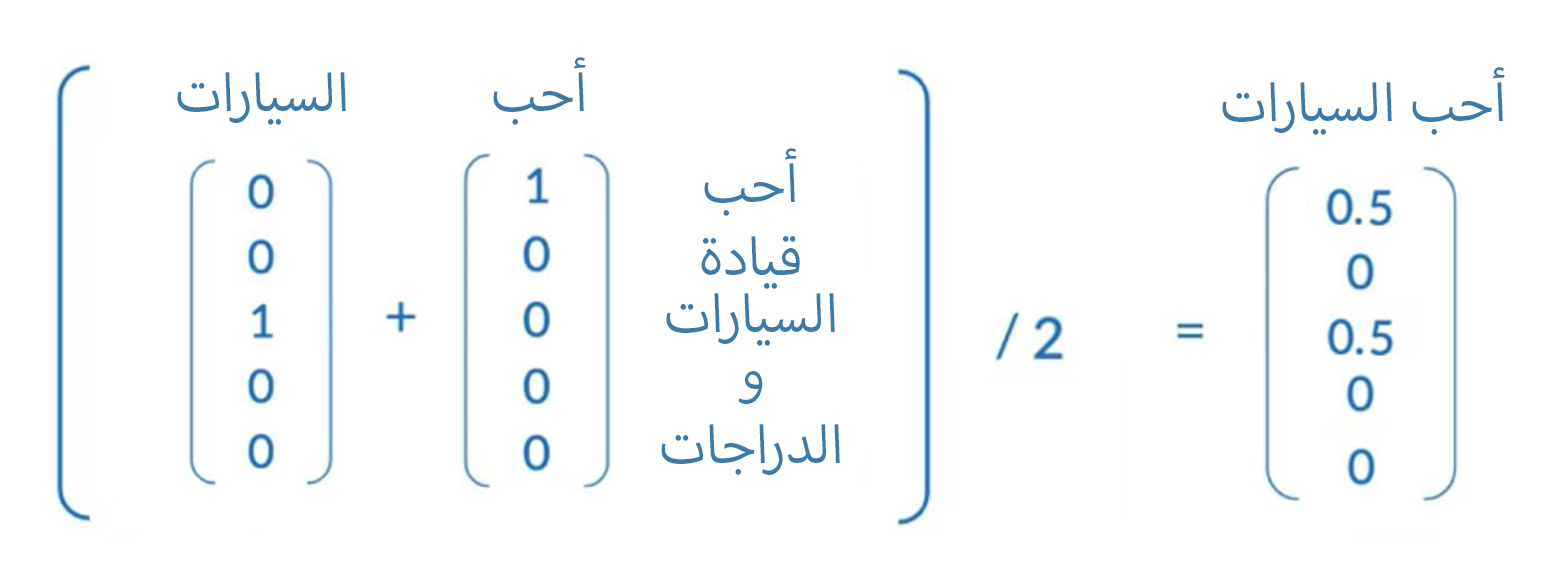
ولتحويل ال (Center word) لن نحتاج لهذا ، فهي كلمة واحدة
مثال : ال (center words) المثال بالأعلى
'قيادة'
وقيمة المتجه الخاص بها لن تتغير
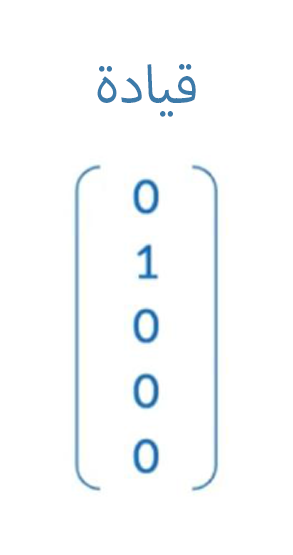
الشكل النهائي لـ Dataset
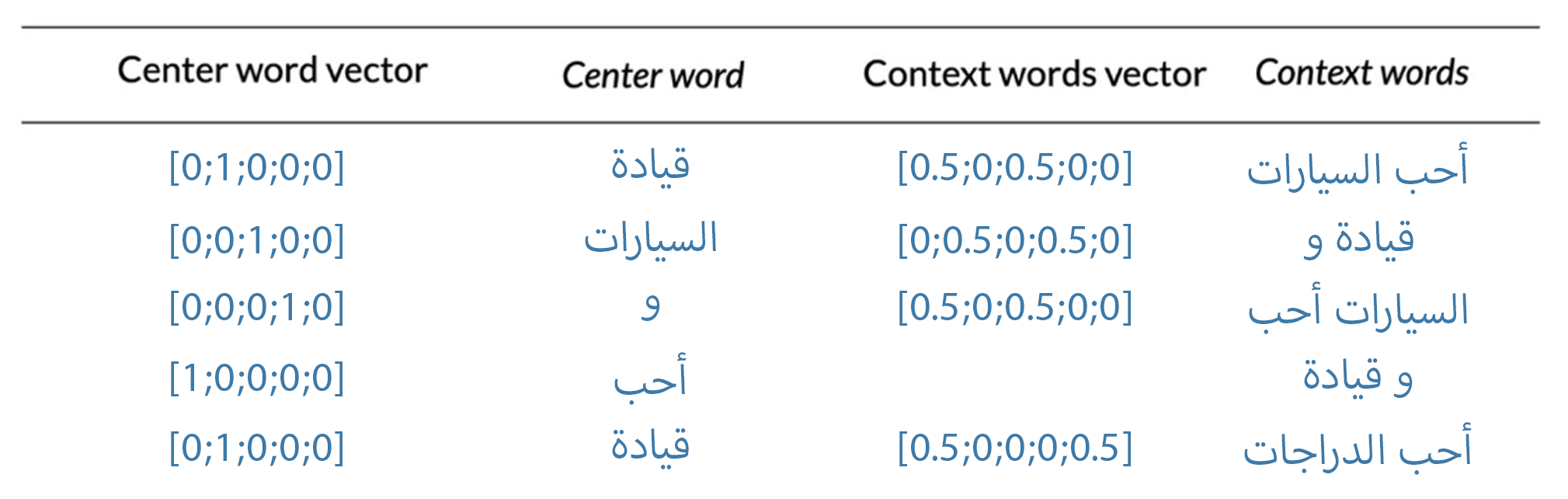
الهيكل البنائي لل model الخاص بال CBOW
يتكون ال model باستخدام ما يعرف بال (Shallow neural networks) أو الشبكات التي تتكون من عدد صغير جدا من الطبقات (layers)،
ستكون هنا الشبكة الخاصة بال CBOW من ثلاثة مراحل (layers) فقط. المرحلة الاولى ستكون للمدخلات (input layer)، والمرحلة الثانية أو الداخلية (hidden layers)، والمرحلة الثالثة المخرجات (output layer).
عدد العصبونات (node or neurons) في المرحلة الاولى والاخيرة سيكون متساوي ، حيث انها تساوي عدد الكلمات بدون تكرار في الـ (dataset)
بالنسبة للمرحلة الثانية سيكون عدد العصبونات فيها اختياري كما شرحنا سابقا،
الأبعاد الخاصة بكل مرحلة
- Vocabulary size = V
- input layer = V*1
- output layer = V*1
- hidden layer = N*1
من تلك الأبعاد يمكن استنتاج الأبعاد الخاصة بال (weights) وتكون كالاتي
- W1 = N*v
- b1 = N*1
- W2 = V*N
- b2 = V*1
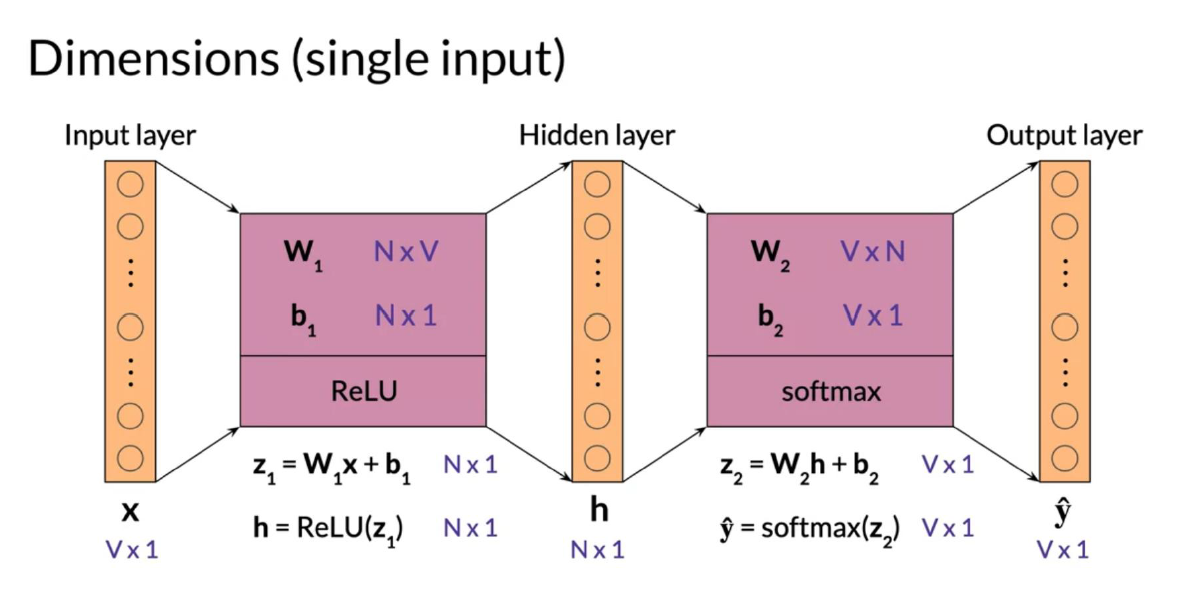
ولكن عند استخدام الـ batch inputs ستتغير الابعاد قليلا ، لتناسب عدد ال batches
- Vocabulary size = V
- Batch size = m
- input layer = V*m
- output layer = V*m
- hidden layer = N*m
هنا لن يتغير الابعد الخاصة ب (W1 , W2)
- b2 = V*m
- b2 = V*m
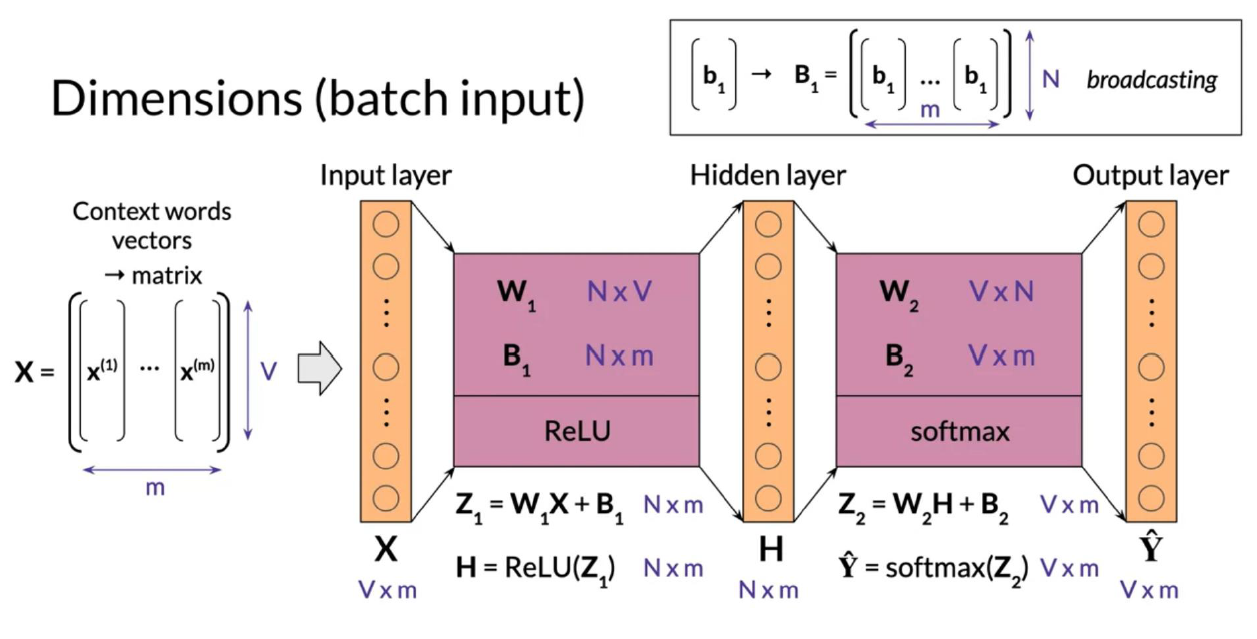
عملية التعلم
تنقسم عملية التعلم إلى ثلاث
- 1- Forward Propagation
وهنا يتم إدخال البيانات خلال الشبكة والتنبؤ بالنتائج
في أول الأمر نستخدم قيم عشوائة ل (W1, W2)
def initialize_model(N,V, random_seed=1):
np.random.seed(random_seed)
# W1 has shape (N,V)
W1 = np.random.rand(N,V)
# W2 has shape (V,N)
W2 = np.random.rand(V,N)
# b1 has shape (N,1)
b1 = np.random.rand(N,1)
# b2 has shape (V,1)
b2 = np.random.rand(V,1)
return W1, W2, b1, b2
def forward_prop(x, W1, W2, b1, b2):
# Calculate h
h = np.dot(W1,x)+b1
# Apply the relu on h (store result in h)
h = np.maximum(0,h)
# Calculate z
z = np.dot(W2,h)+b2
return z, h
- 2- Cost
نحسب ال (cost) او ثمن الأخطاء الناتجة من ال (forward propagation) ، فالهدف من عملية التدريب هو تقليل هذه الاخطاء قدر الامكان
def compute_cost(y, yhat, batch_size):
logprobs = np.multiply(np.log(yhat),y) + np.multiply(np.log(1 - yhat), 1 - y)
cost = - 1/batch_size * np.sum(logprobs)
cost = np.squeeze(cost)
return cost
- Backpropagation and gradient descent
فهذه المرحلة نستخدم الـ (Gradient descent) ، لتعديل قيم ال (weights) لتقليل نسبة الخطأ
ان كنت لم تسمع عن (Gradient descent) فأنصح بقراءة هذة المقالة
def back_prop(x, yhat, y, h, W1, W2, b1, b2, batch_size):
# Re-use it whenever you see W2^T (Yhat - Y) used to compute a gradient
l1 = np.dot(W2.T,(yhat-y))
# Apply relu to l1
l1 = np.maximum(0,l1)
# Compute the gradient of W1
grad_W1 = (1/batch_size)*np.dot(l1,x.T)
# Compute the gradient of W2
grad_W2 = (1/batch_size)*np.dot(yhat-y,h.T)
# Compute the gradient of b1
grad_b1 = np.sum((1/batch_size)*np.dot(l1,x.T),axis=1,keepdims=True)
# Compute the gradient of b2
grad_b2 = np.sum((1/batch_size)*np.dot(yhat-y,h.T),axis=1,keepdims=True)
return grad_W1, grad_W2, grad_b1, grad_b2
ويمكن تلخيص هذه العملية من خلال الصورة بالاسفل
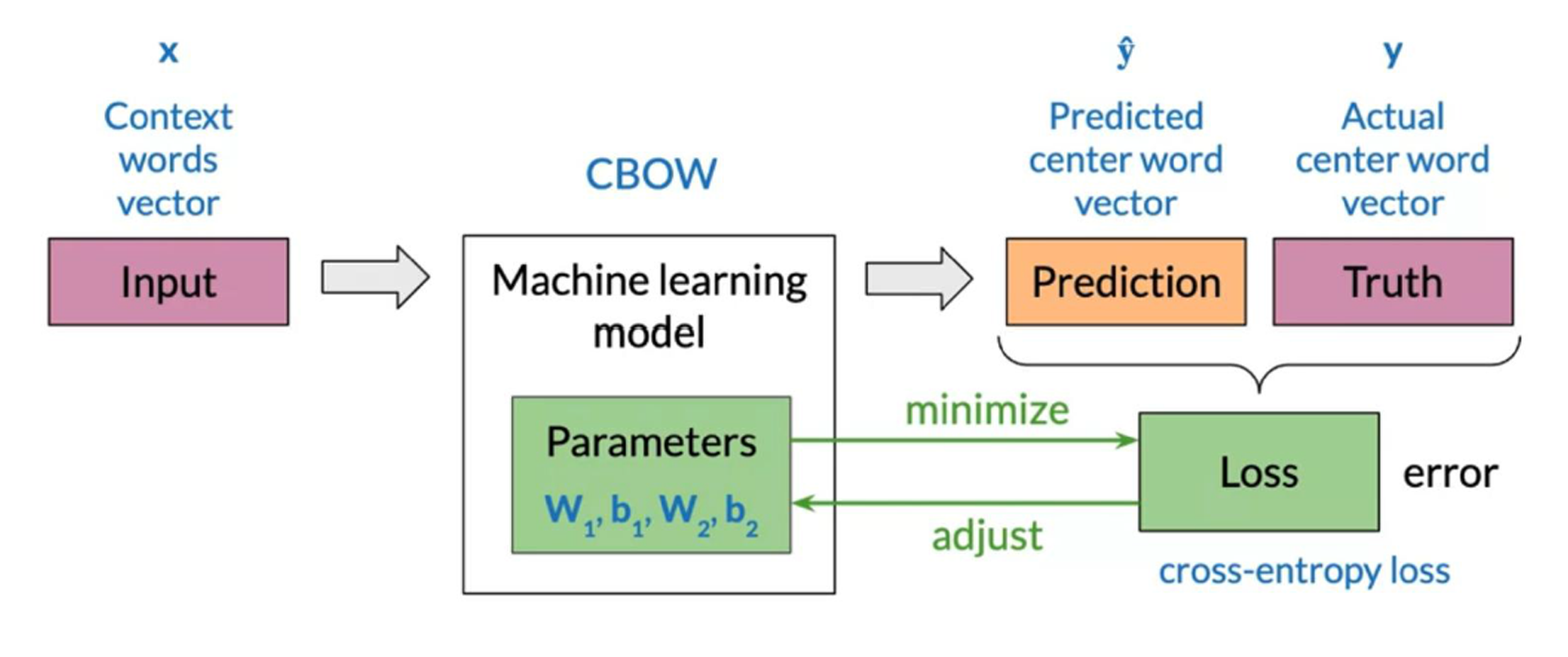
الان بعد ان انتهينا من المفاهيم الاساسية اللازمة للتطبيق ، لنناقش الآن بعض المتغيرات التي سيتوقف عليها نتائج الموديل
- ١- عدد كلمات ال (Context words)
عن تغير هذا المعامل ستتغير الكفاءة النهائية ، سنستخدم هنا قيمة المعامل ب 2 (C)
- ٢- ابعاد ال (word embeddings)
ستستخدم هنا متجه بشكل (300*1)
- ٣- معامل التعلم
سنستخدم هنا معامل قيمته .03 وسيقل بمقدار .66 في كل لفة ،
- ٤- عدد اللفات
سنستخدم هنا عدًد اللفات ب 20
def gradient_descent(data, word2Ind, N, V, num_iters, C=2, batch_size=128, alpha=0.03):
W1, W2, b1, b2 = initialize_model(N,V, random_seed=282)
batch_size = batch_size
iters = 0
C = C
for x, y in get_batches(data, word2Ind, V, C, batch_size):
# Get z and h
z, h = forward_prop(x, W1, W2, b1, b2)
# Get yhat
yhat = softmax(z)
# Get cost
cost = compute_cost(y, yhat, batch_size)
if ( (iters+1) % 2 == 0):
print(f"iters: {iters + 1} cost: {cost:.6f}")
# Get gradients
grad_W1, grad_W2, grad_b1, grad_b2 = back_prop(x, yhat, y, h, W1, W2, b1, b2, batch_size)
# Update weights and biases
W1 -= alpha*grad_W1
W2 -= alpha*grad_W2
b1 -= alpha*grad_b1
b2 -= alpha*grad_b2
iters += 1
if iters == num_iters:
break
if iters % 100 == 0:
alpha *= 0.66
return W1, W2, b1, b2
C = 2
batch_size = 128
# getdict is o=holding the words and its index
word2Ind = get_dict(data)
V = len(word2Ind)
num_iters = 20
print("Call gradient_descent")
W1, W2, b1, b2 = gradient_descent(data, word2Ind, N, V, num_iters, C, batch_size)
النتيجة
Call gradient_descent
iters: 2 cost: 14.706067
iters: 4 cost: 0.004671
iters: 6 cost: 0.004275
iters: 8 cost: 0.003942
iters: 10 cost: 0.003657
iters: 12 cost: 0.003411
iters: 14 cost: 0.003196
iters: 16 cost: 0.003007
iters: 18 cost: 0.002839
iters: 20 cost: 0.002689
جميع الاكواد المستخدمة ستجدها هنا على حسابي الخاص على github
استخراج ال Word Embeddings
يوجد ثلاث اختيارات يمكننا بيها استخراج ال word embeddings
- ١- من خلال W1
- ٢- من خلال W2
- ٣- من خلال متوسط القيم بين (W1 , W2)
تقييم كفاءة ال word embeddings
- 1- Intrinsic Evaluation
ينقسم الي قسمين
- 1- Analogies
ينقسم الي عدة انواع، تعتمد جميعها على المعنى الكلمات
- a- Semantic analogies
ويعتمد على المقارنات الدلالية بين الألفاظ ، مثال
علاقة "باريس" بالنسبة "لفرنسا" ، مثل علاقة "القاهرة" بالنسبة __؟___
- b- Syntactic analogies
علاقة كلمة "يلعب" بالنسبة لكلمة "لعب" ،مثل العلاقة بين كلمة "يشاهد" وكلمة __؟__ - 2- Clustering
نستخدم فيها خوارزمية التجميع (clustering)، لنتختبر مدى تجانس الكلمات
- 2- Visualization
نستخدم هنا الادوات المختلفة لصناعة مخرجات مرئية يمننا من خلالها استنتاج كفاءة ال model
- 2- Extrinsic Evaluation
تعتمد هنا على استخدام ال (word embeddings) في تطبيقات اخرى في علممعالجة اللغات الطبيعية مثل (NER, Sentiment analysis)
ولكن تلك الطريقة بها بعض العيوب وهي استهلاك الكثير من الوقت، وعند حدوث أخطاء لن تستطيع تحديد مكان الخطأ ، هل هو من الخوارزمية ام من ال word embeddings
تحديد كفاءة ال model المستخدم في هذا المقال
في هذا المقال كما ذكرت سالفا ،لقد طبقت طريقة ال CBOW على اللغة العربية ،ولقد ترتك رابط للاكواد المستخدمة هنا لتساعدك في تدريب الmodel الخاص بك ،
وسنناقش الان الكفاءة الخاصة بذلك الموديل من خلال ال Visulization و ال Analogies
- 1- Visulization
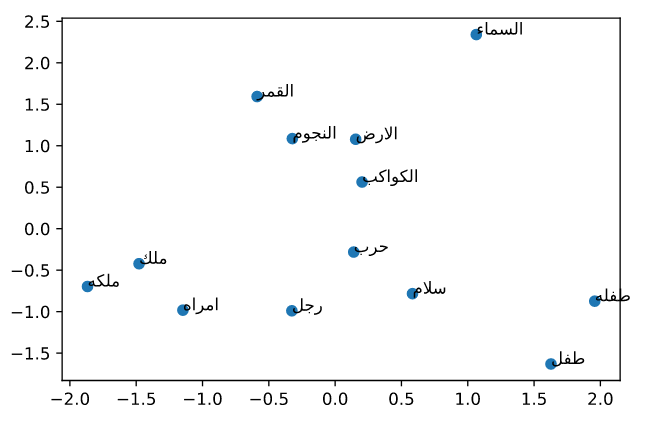
سنختار عدد كلمات لنرسمها على محورين ، ولن هناك مشكلة وهي ان اعبعاد ال word embeddings المستخدمة 300 ،لذلك سنستخدم تقنية ال PCA لتحويل الابعاد ال 300 لبعدين فقط
الكلمات المستخدمة :
['ملك','ملكه','رجل','امراه','طفل','طفله','حرب','سلام','الارض','السماء','الكواكب','النجوم','القمر',]
Leave a comment